0 – Introduction
“Investigate, test and iterate.”
When we talk about analytics and machine learning, it is the new thing that replaces the old systems, perhaps a transition from traditional and manual marketing to automated and personalised sendouts. While the big picture is essential, the transition from unpersonalised to personalised can usually only happen once! So how do you go about improving your systems when there are no transitions left to do?
In this blog post, I want to talk about a situation that arises when the big transition project is over, and you have implemented all the new tools, and it’s time to improve one of your models. Maybe you have a model for predicting sales volumes, identifying churning customers, or personalised product recommendations in your newsletter. Improving predictions or recommendations by a single per cent might seem insignificant. Still, when you have hundreds of thousands of customers, such a slight improvement can amount to a lot of value!
Regardless of the purpose and technicalities working under the hood (e.g. collaborative filtering, random forest, logistic regression or any other type of model), you can almost surely improve your model. One easy way to enhance a model is to add a neat new feature (aka input column) or rework an existing one. Let’s outline how this could work in practice with some steps and examples.
1 – Looking for ideas
Perhaps you already have a hunch about something that you think would improve the model. Maybe you get a lot of customer feedback that they have some preference that you are ignoring. For instance, they might complain about vegetarians and send them promotions for non-vegetarian food items.
Otherwise, you can hold a brainstorming session with some colleagues to see if you can use your combined understanding of your business to come up with something that could add value to the models. Many things that come naturally to us humans (what we call “common sense”) are hard for a computer to grasp unless you specify it in some intelligent way. It is hard to figure out ways to encode things relevant to the business into data that is processable by the model, but it is at the core of data science. Let’s look at an example.
Suppose you are selling sports equipment online. A human would probably not suggest buying wool hats or new ice skates in the summer, even if the targeted customer is an avid skater in the winter. Still, the model might not be “aware” of this seasonal tendency and give suggestions that are perfect for a skier – but entirely wrong for the season.
2 – Investigating the data
The next step is to dig into the data to investigate what you think would be a helpful feature. The benefit of this investigative work is that you might uncover even more powerful connections in the data. You might also find out early if the potential new feature is a dead end. The whole point of having data is that you don’t have to guess! If you see something interesting in the data, investigate it! You might have an intuition for which features will be of importance, but unless you take a closer look at the data – and test your ideas out – you will never know.
Try to collect your findings in a presentable format as if you wanted to convince someone else about your reasoning and what you have found. This makes it easier to see if the thought process is sound and if there are any aspects that you have missed!
To return to the sports shop example, let’s imagine that we are trying to figure out ways to measure seasonal effects. A good start would be to calculate the sales of a product per month or week compared to the yearly average – let’s call it relative sales – which we can plot. The following figure illustrates what we might see:
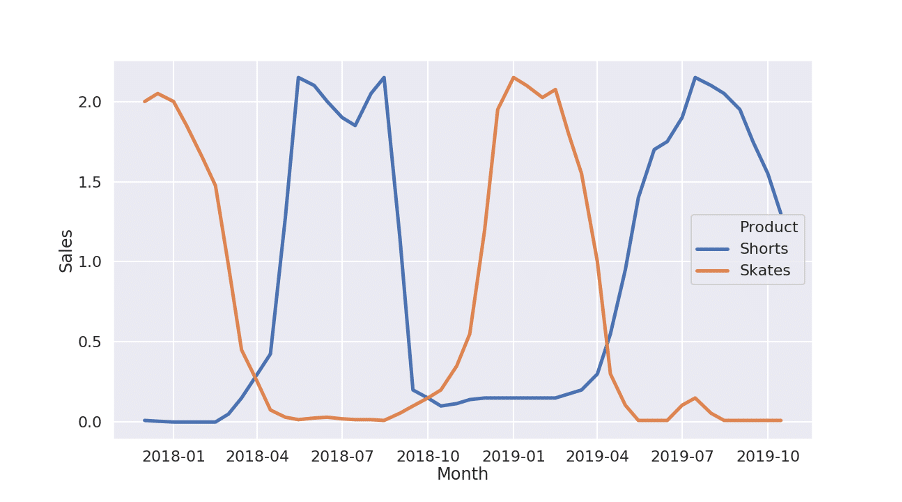
Figure 1: From this plot, it would seem there are valuable insights to gain!
3 – Implementation and testing
Now that you (and your colleagues) are convinced that your idea is good, it’s time to make it happen. Depending on the technical environment you are using, the complexity of implementing the new feature can vary.
Once your feature is ready to go, it’s time for some machine learning! This means creating new datasets that include the new feature (as well as the old ones), training the model with these new datasets and evaluating the results.
Something to keep in mind when working with seasonal data, as in our example above, is that Easter, in contrast to, e.g. Christmas and Midsummer, happens at different dates every year, which can give you very strange results if you aren’t careful.
4 – Running your model for real
Be prepared: the most likely outcome of the previous step is that you will have to tweak something, fix some bugs and do it all over again.
But for the sake of brevity, let’s imagine it all went smoothly, and every metric indicates the model is better with your new feature than it was before. At this stage, you should think about the following and arguably most important step, which is to do some real-world testing.
Depending on the situation, you might not want to do a full-scale AB-test using your new model on half of the customers right away. In such circumstances, it might be preferable to test only on a small percentage of the customer base, perhaps 5% or 10%.
Testing is a deep topic worth a post of its own, so I’ll leave that discussion for later. But remember that no matter how good the model looks when you are training it, the real world is a whole different beast, and the only way to know how a model performs is to test it. There is always room for improvement, and when the customer base is getting bigger, even minor improvements can give significant results. So don’t stop evaluating and improving your models!