Making significant top- or bottom-line gains via digital marketing & sales requires insights and intelligence deriving from the ability to identify users online on a personal level and tailor your marketing communications based on customer data. Today, very few companies in Northern Europe have been able to tap into the potential of combining online and customer data at scale. These capabilities cannot be developed overnight but require a combination of a long term vision and unrelenting determination. Once in place, your data capabilities will provide a significant advantage over your less savvy competition. They will also level the field with data-native-digital first competitors. In this blog, you will familiarise yourself with:
- Key benefits of combining your online and customer data
- High level technical and compliance requirements
- How to maximise your base of identifiable customers and prospects in online channels
Defining future success for a marketeer navigating in an ever digitising environment, we define this as the most important piece in the puzzle to increase both the value of your customer data sets or the ability to turn them actionable. Since online and offline customer experiences are merging inevitably, understanding customer behaviour across channels is a must-win battle providing a ticket to play independent of industry or b2c versus b2b context. We’ve asked Google representatives to give examples of companies in the Nordics who have managed to utilise customer data within digital touchpoints, even on a small scale. The closest example we got was from the Netherlands. In this case, the example given was Rituals.
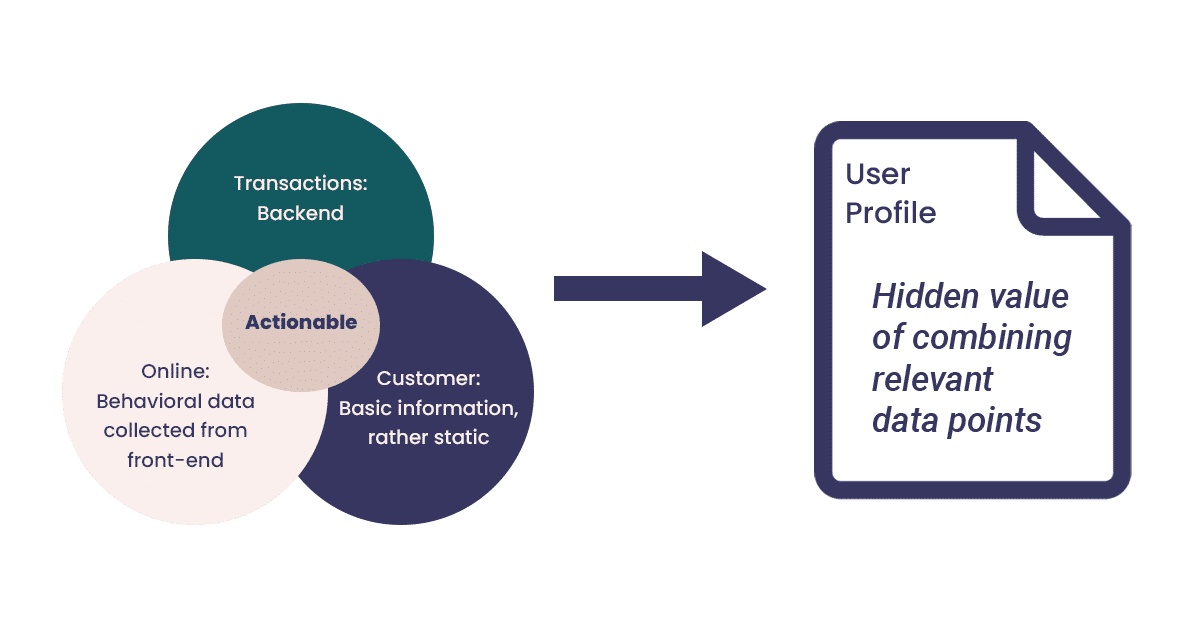
Key Benefits of Combining your Online and Customer Data Sources
Web analytics, or the measurement of online behaviour, has from its origins been relying on browsers or devices instead of thoroughly trying to understand the user or human being behind that device. Despite growing challenges in online tracking and privacy concerns, we’re an optimist in the sense of believing both technology and corporate responsibility to solve rising concerns over espionage.
To exemplify the benefits of combining online behavioural data sets with customer data sources, we have divided the benefits into four main categories:
- Building a “most precise” user profile (sometimes misleadingly referred to as the Customer 360)
- New and better customer insight
- Marketing efficiency, improved results for sales & marketing activities
- Backbone and accuracy for Predictive Analytics or Machine Learning solutions
Customer 360 being an overused promise never delivered by any technology or service provider, I want to highlight the perspective of acquiring new insight into customer behaviour. Combining observations of behaviour across channels with knowing different attributes like basic customer characteristics should lead to new insights. Otherwise, the analysis part has failed. But the actual value of this insight is to make it actionable and create customer-facing actions based on the newly acquired finding. The more you can find new insights and take action upon them, and the more value is created. Scaling needs automation, which will be discussed separately in the following post of this blog series.
An Actionable User Profile is a Layer Driving Business Impact
When talking during the past 12 months with Executives and Technology vendors, we’ve spotted one common and very fundamental misconception when it comes to combining online and customer data sets. If all the data is not stored in one “physical” place, it’s perceived that these data sources are not combined at all. Whereas we’re claiming that it doesn’t even have any purpose of combining all data, only relevant data points serving a clear defined use case. Additionally, following data minimisation principles given by GDPR, it makes even more sense to focus only on specific data points being actually used.
One could take many perspectives into the combination logic, but the first to start with is to define whether you are combining online behavioural data with the customer and transactional data or vice versa. This has huge practical implications. Suppose online behavioural data is the starting point. In that case, it makes sense to enrich it with purposeful customer data elements, for example, within custom dimensions (or similar variables), where online behavioural data is kept in raw event-level format, and customer data is pre-processed for enrichment purposes. The other way around, a customer profile could be enriched with online behavioural triggers indicating certain behaviour, again serving a clear use case.
One of the biggest misconceptions is that all data should be physically stored together to be combined and actionable.
When discussing with experts or professionals within the data field, there are constantly popping up questions about Lakes of Data (aka Data Lakes). Dumping raw data sets into a common platform to be stored doesn’t make them combined or add any value in itself. This brings us to the interesting question of how actually to combine these data sources.
Requirements from a Technical Perspective are Straightforward but Require a systematic Approach
To identify users online, you need to capture a person identifier, often referred to as a PII-data point, and combine it with an online identifier, like some of the identifiers used by commonly used web analytics tools or a custom-built one. These person identifiers can be captured besides users logging in to your services whenever they provide data via forms, chats, calculators or similar. One way to increase the amount of online identifier and person identifier value pairs is to embed a pseudonymised person identifier into a communication like an email sent out triggered by knowing the receiver. When a user interacts with this communication where a person identifier is embedded, the event can be captured as part of online behavioural data capture, which establishes a value pair to be further used for combining data sets.
Since users can be identified by several different methodologies as described above and none of the individual ways enables to identify all users, a systematic approach is required to maximise the potential to combine online behavioural data with customer data for any use case you are interested in. This systematic approach requires long-term strategic thinking and willingness to invest in a value-driving data asset.
The hard part is that you don’t want to expose these person identifiers in a format that as itself reveals somebody’s personal identity, since that way these person identifiers could lead to third parties, which with high likelihood can in most cases be classified as a data breach. Also, most cloud-based SaaS marketing tools deny the processing of PII-data (not to be mixed up with personal data) within their platforms. A secure way is to pseudonymise PII-data points when capturing them and doing that in a secure way.
Too often anonymisation and pseudonymisation gets mixed with each other.
To be clear, it’s important to distinguish between anonymisation and pseudonymisation. Anonymisation stands for transforming a data point to stay anonymous, disabling the possibility of reverting the anonymisation process. Pseudonymisation instead enables translating a data point back to its original format having a key for reverting the process. The pseudonymisation process should be from a security perspective so strong, that the reversion process can only be done via a translation key. This process of reverting pseudonymised PII-data elements plays a key role in enriching online behavioural data with customer attributes, or vice versa. If the process is designed well, it also allows a high degree of automation, scalability in practice.
Strict Legal Requirements for Marketing Purposes
In our earlier introduction into the ten building blocks for and actionable marketing data-asset – the Avaus Factory, we referred to the legal grounds looking at the environment how the GDPR legislation is currently being interpreted. Collecting, storing and combining data sets always require valid legal grounds to be processed in a compliant manner. There are not so many alternatives to choose from, either legitimate interest, consent given by the data subject or fulfilment of contractual obligations.
Ten Building Blocks for an Actionable Marketing Data-asset
What is for sure to claim, combining online behavioural data with customer data for activation and marketing purposes in any channel, requires a consent that can be revoked. The consent needs to meet audit trail requirements too. Hereby by audit trail is meant the ability to prove when and who has given a consent and for which purpose. The same applies for revoking a consent.
For audit trail purposes it is most probably best to keep a separate record for consents in a consent repository, built to be flexible to changes either in compliance or business requirements. For practical use it might make sense to build the legal grounds of data processing also natively into your data sets for operational purposes, enabling the end user having the information how to use data easily available or enabling packing data into data products for end users tailored by use cases or use case categories.
Many Marketing Automation tools have inbuilt features to track automatically online behaviour combined with a person identifier, most commonly email address. Although this is a very practical feature, it embeds many risks that easily get ignored either due to lack of awareness or a strictly defined Privacy Framework. Additionally, despite providing easy to digest and useful information, the actual data can rarely be used to its full potential. This is due to the ability to further manipulate the data outside the Marketing Automation tool in flexible ways, the ability to combine it with other data sources and compliance restrictions hopefully spotted before any harm is caused for the Data Subject or Data Controller.
How to Combine Data Sets in Practise Should be Defined by Use cases
The first consideration when combining data sets is to define what is the primary focus in terms of use cases and are you combining online behavioural data with customer data (other data sources) or vice versa. These perspectives are not either or, you might have both perspectives as separate processes serving different use cases. But the chosen perspective defines the logic of how technically data sets are combined, what data points to actually combine and how to handle compliance responsibilities, like consent values.
Examples of concrete use cases could be as follows:
- Analysis of online services based on customer segments for conversion optimisation and improving experience of digital applications.
- Advertising targeting / exclusions using customer data across digital channels like Search Engines, Display, YouTube / Video or Social Media.
- Triggering customer facing activities in 1-to-1 channels based on observed behaviour like e-mail, SMS, push notifications, telesales etc.
- Producing more accurate predictions using advanced analytics or machine learning regarding propensities for converting / buying, reacting to communications, churning or any similar interesting predictions.
- Recommendations for relevant content, products, services and Next Best Actions.
All of these use case examples could follow a different approach in how to follow the principle of bringing relevant data points serving the set targets for the given use case. Clearly you can make a distinction between two types of use cases, one focusing and creating on action, another on delivering analytical insights. Whilst aiming for insight creation it’s good to keep in mind enabling their actionability as an ultimate outcome.
When considering activation, a key driver for data model design is whether an activity needs to be done on an individual person level or for a group or segment of individuals. This is also a fundamental design choice for the PII-data pseudonymisation capability needed to create online and person identifier value pairs. Besides enriching profiles either with online behavioural data or customer data attributes, data access principles from a compliance perspective need to be evaluated carefully. Compliance questions unfortunately don’t have any silver bullet solutions, instead they need to be evaluated as part of a Privacy Framework design, case by case.
Schrems II Might Complicate the Process of Combining Data Sets
The EU court ruling over the Schrems II case invalidating the earlier Privacy Shield agreement forces companies at least to consider how to actually pair online behavioural data with customer data which especially is treated as personal data, also in pseudonymised format. The critical question is whether you have control over where geographically data is being processed. Many MarTech platforms used for data collection on online touch points don’t give any control over data processing location. Public cloud vendors instead give much more choice and flexibility to choose either on regions or even single data centers around the globe.
Therefore you might want to reconsider the logic of how to pair online and customer identifiers, where that pairing happens both in a technical data flow and where those value pairs are processed. If the pairing of online identifiers and personal identifiers is done on a platform where location of data processing is not directly controlled by you as a marketer and Data Controller, I strongly advise you to clarify within your company legal department & business stakeholders the exact definitions of personal data. There are different interpretations how identifiers especially in the online universe are treated whereas Personally Identifiable Data is always personal data in legal terms, being in plain text or pseudonymised.
By embracing a Privacy First approach and applying privacy by design principles, I can see these complications too to be solved if you focus on building your data capabilities properly. Here the proactivity principle plays a key role and the flexibility inbuilt into data processing logic being able to adapt to changes in environment, either regulatory or technological. Flexibility is particularly the ability to make changes in the online and customer value pairing logic. The rapid adaptation and development of server side tracking is crucial to master, having more control over data collection logic and enabling the flexibility mentioned above.
Success is Defined by the Ability to Identify Users Online on Person Level
The impact of use cases and customer journeys built around combining online behaviour with other customer or transactional data is highly impacted by the ability to identify users online, logged in or not. It’s relevant to ask the question aloud, how many companies across the Nordics have a clear defined KPI of identified online users? I doubt that now too many unfortunately. Since the ability to identify users online is such an important KPI for use case success it should not let for luck or randomness to be defined. There are several ways to identify users systematically besides them directly logging in to any services. If you have sufficient legal grounds or consent in place, each time interacting for example via push communication can be used to link online identifiers with persons identifiers. Also all touchpoints where the user is giving voluntarily personal identifiable information for any given purpose, those are the moments you should pay attention to. At the same time the level of identification needs to be kept in mind, specifically defining what level of identification each use case requires strong authentication for example via bank id being on the one extreme and playing with probabilities on the other.
Another critical KPI defining the impact of use cases relying on combining online behavioural data with customer data is the amount of identified individual “data subjects” in legal terms, that have opted in whatever you have been asking consent for. To maximise the amount of consents and opt-in rate, it pays off to consider how to collect the consent in first hand. A very logical approach would be to focus on the channel where you reach the most of your audiences, where the user doesn’t need to be yet in an identified state. Besides existing customers, to maximise impact of identifying potential customers as data subjects is worth considering too. Besides a systematic approach towards a business driven KPI, it’s worth remembering being transparent towards users not only fulfilling GDPR requirements, but to build trust which is hard to earn if losing it due to any reason.
I strongly recommend to start the journey in utilising the valuable insights of combining online behavioural data with customer data. You will eventually see a big impact in increased ROI of your investments in providing relevant customer experience across channels your customers and potential customers prefer.
*Views and opinions presented in this blog don’t represent any legal advice provided by Avaus Marketing Innovations.
Please reach out to us if you wish to get further information.