Azure Data Factory is, in many cases, the go-to service when orchestrating data to and from an Azure instance. We say “orchestrating” because, until recently, there hasn’t been a direct way to make any actual transformation (as in ETL) of your data.
Sure, Azure DataBricks has been a part of the Azure offering for some years now, but to be able to use it, you must write Python or Scala code to process the data. Nothing wrong with that, and the evangelist will probably still prefer this, but it is not necessarily super convenient in every situation.
To tackle this, Microsoft’s Azure Data Factory (ADF) team have recently released Azure Data Flow, which acts as an “SSIS in the cloud” (SQL Server Integration Service). Azure Data Flow enables the Data Factory to work as a proper ETL tool. Azure Data Flow is a ”drag and drops” solution (don’t hate it yet) that gives the user, with no coding required, a visual representation of the data “flow” and transformations being done. As usual, when working in Azure, you create your “Linked Services” – where the data is coming from and where it is going. From there, you build your flow step-by-step until the data satisfies your needs. Transformations that you would usually do by creating a stored procedure and running on the loaded data at destination are now all managed in your Data Factory, thus making your warehouse cleaner and more ready-for-use. The graphic below shows an example of a Data Flow.
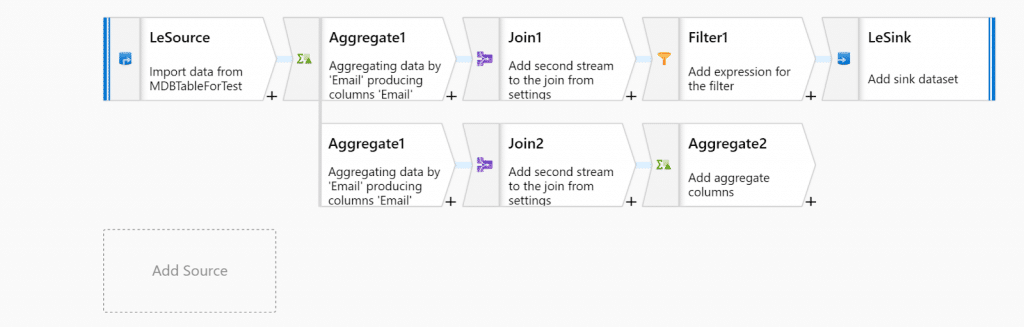
An example of a Data Flow is where the data is collected, aggregated, joined to a secondary stream, filtered, and stored to a designated sink.
Like most things in the cloud, you are somewhat limited in what you are allowed to do. Even so, Data Flow only will enable you to use the prebuilt operations for your transformations. Data Flow is under development to expect more operations and capabilities. Data Flow will probably never be a messiah, but maybe something close to Batman.
We mentioned DataBricks earlier. Data Flow is an extension of Azure DataBricks. Data Flow generates a JSON file out of your work in Data Factory. The JSON file is passed on to DataBricks as a blueprint. DataBricks generates equivalent Scala code that is passed on as a job, and the Scala code is finally executed on the cluster (previously defined) using Spark. Azure Data Factory manages code translation, spark optimisation, and executions and automatically scales out nearing completion.
Azure Data Flow is currently in public preview (aka not quite complete), but in its current state, the following operations are available:
- Join – Join several data streams on a condition
- Split – Routing of data to different streams based on a condition
- Union – Collecting data from streams
- Lookup – Looking up data from another stream
- Derived Columns – Create columns based on already existing ones
- Aggregates – Aggregate data
- Surrogate Keys – Add a surrogate key column for a specific value
- Exists – Check if data exists in another stream
- Select – Select which data should go to the next stream
- Filter – Apply filters to the streams
- Sort – Orders the data in the stream
“We are stuck with technology when what we want is just stuff that works” – Douglas Adams
Contact us